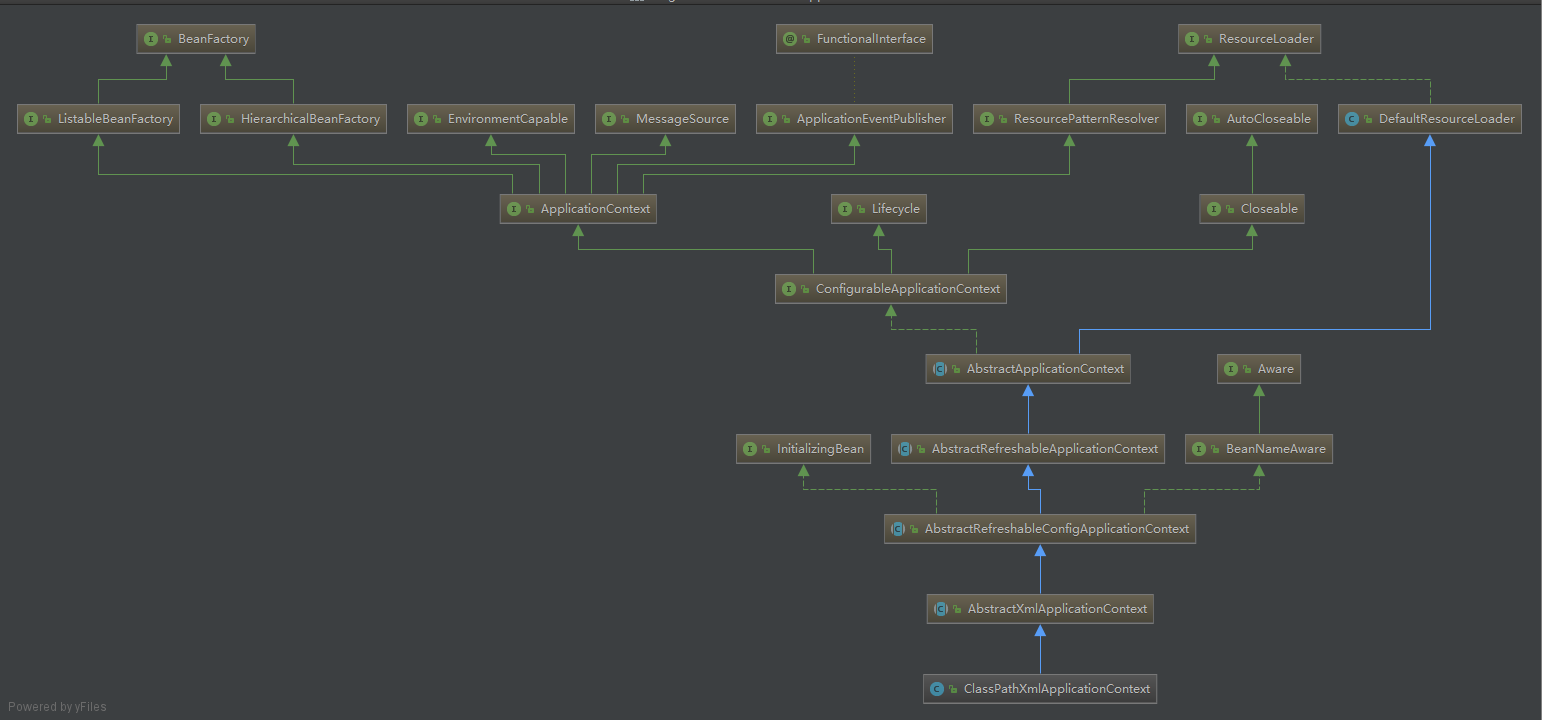
1. 线程状态 一张图详解java多线程的多种状态以及状态之间的关系
2. 多线程的实现方式 在java应用中,共有8中实现多线程的方式,如果是spring应用,还可以有spring的基于注解的多线程开启方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.*;
@Configuration
@ComponentScan ()
@EnableAsync
public class Main
static class Demo1 extends Thread
@Override
public void run ()
System.out.println("Thread change run implements running ...." );
}
}
static class Demo2 implements Runnable
@Override
public void run ()
try {
Thread.sleep(3000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Runnable implements method ... " );
}
}
static class Demo3 implements Callable <Integer >
@Override
public Integer call () throws Exception
System.out.println("返回值的方式创建线程" );
Thread.sleep(3000 );
System.out.println("返回值的方式创建线程" );
return 1 ;
}
}
@Service
class Demo4
@Async
public void printA () throws InterruptedException
while (true ) {
Thread.sleep(300 );
System.out.println("a" );
}
}
@Async
public void printB () throws InterruptedException
while (true ) {
Thread.sleep(300 );
System.out.println("b" );
}
}
}
public static void main (String[] args) throws ExecutionException, InterruptedException
Demo1 demo1 = new Demo1();
demo1.run();
Thread thread = new Thread(new Demo2());
thread.start();
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Demo3());
Thread thread1 = new Thread(futureTask);
thread1.start();
System.out.println("结束了吗?" );
System.out.println("计算的结果: " + futureTask.get());
Thread thread2 = new Thread(new Runnable() {
@Override
public void run ()
System.out.println("匿名内部类的方式创建线程!!!" );
}
});
thread2.start();
Thread thread3 = new Thread(){
@Override
public void run ()
System.out.println("重写run方法" );
}
};
thread3.start();
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(Main.class);
Demo4 threadService = applicationContext.getBean(Demo4.class);
threadService.printA();
threadService.printB();
List<Integer> lists = new ArrayList<Integer>(){
{
add(1 );
add(2 );
add(3 );
add(4 );
}
};
lists.parallelStream().forEach(System.out :: println);
ExecutorService executorService = Executors.newFixedThreadPool(10 );
for (int i=0 ; i<100 ; i++){
executorService.execute(new Runnable() {
@Override
public void run ()
System.out.println(Thread.currentThread().getName());
}
});
}
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run ()
System.out.println("定时器的多线程" );
}
},1000 ,3000 );
}
}
3.线程安全性问题 先来了解一下java多线程引发安全问题的3个前提
多线程条件下
有共享资源
非原子性操作
看个例子1
2
3
4
5
6
7
8
9
10
11
public class SingletonHungry
private SingletonHungry ()
private static SingletonHungry singletonHungry = new SingletonHungry();
public static SingletonHungry getSingletonHungry ()
return singletonHungry;
}
}
这是典型的饿汉式单例模式,不存在线程安全性问题,因为getSingletonHungry()方法是原子性的。再看一个懒汉式的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class SingletonLazy
private SingletonLazy ()
private static SingletonLazy singletonLazy;
public static SingletonLazy getSingletonLazy () throws InterruptedException
if (singletonLazy == null ){
synchronized (SingletonLazy.class){
if (singletonLazy == null ){
singletonLazy = new SingletonLazy();
}
}
}
return singletonLazy;
}
}
表面看这个代码没问题,也加了锁,但是这里还有一个涉及到指令重排序 的问题,就是说jvm执行上述代码的时候并不一定是按照正常顺序来执行的。比如,正常来讲,jvm实例化对象是首先申请一块内存,然后实例化对象,最后再指向对象。然而经过指令重排序的优化过程,有可能会先实例化对象,再去执行其他步骤,这样就可能造成第二个if(singletonLazy == null)的判断不准确。所以这里需要给singletonLazy加个 volatile 关键字,意思是不给这个对象进行指令重排序等jvm执行优化操作。
偏向锁:jvm执行引擎会一直获取锁信息,只有当发生竞争的时候,它才会放弃锁,然后再重新获取对象锁信息(锁信息保存在对象头 中)。相比较以前每次进入方法前都需要获取锁信息操作性能提升了不少
轻量级锁: 在多线程竞争的环境下,线程尝试获取被加锁的对象时,会先将对象头(里面包含对象的锁信息)复制一份,然后尝试获取对象锁,如果获取锁失败,再重复一次复制操作。这叫做自旋锁。直到获取成功。
重量级锁: 多次自旋操作失败后就会升级为重量级锁。
参考:Java并发编程:Synchronized底层优化(偏向锁、轻量级锁)
3.1 synchorized synchroized从1.6开始变得不再像以前那么的重量级了,它有三个转变阶段,分别为偏向锁,轻量级锁,重量级锁。它的主要作用是锁住对象,保证只有一个线程能获取到该对象的实例 ,从而保证线程安全。它可以使用在方法体中和方法声明中,在方法声明中代表的是锁住这个类的对象,方法体中看实现可以随意锁住某个对象。日常使用建议锁的细粒度越细越好。以前jdk中的Vector类就是通过锁方法而保证线程安全的,现在已经不再使用它了,而Collections中以synchronized 开头的方法锁的是一个mutex对象,而不是类对象。1
2
3
public E get (int index)
synchronized (mutex) {return list.get(index);}
}
Vector的部分方法1
2
3
4
5
6
7
8
9
10
11
public synchronized int capacity ()
return elementData.length;
}
public synchronized int size ()
return elementCount;
}
3.2 volatile 关键字 有时候只需要保证共享变量在各个线程中的数据的一致性,就不需要使用synchorized这个锁了,只需要在变量声明时加上volatile关键词就行了,JMM实现了对volatile的保证:对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作,它的汇编语义就是一个Lock指令,这个指令会将CPU里的缓存写入系统内存。所以每个线程读取到的数据都是一致的。然而这样也有一个弊端,随着CPU的三级缓存越来越重要了,这样做无非会降低系统的性能。而且volatile的使用也有一个条件,变量真正独立于其他变量和自己以前的值。比如什么 x++ 操作就不行,依赖于以前的x值。 具体使用请参考正确使用 Volatile 变量
3.3 Lock 锁 lock更强调的是锁住代码块,与对象无关。而且他的实现更有针对性。由于是java实现的,所以它拥有许多synchorized没有的特性,比如说公平与非公平锁(内部维护一个FIFO队列)。
ReentrantLock 这是Lock的一个常用实现,身为一个可重入锁,底层是基于AQS实现的,使用也很简单1
2
3
4
5
6
7
8
9
10
11
12
13
public class ReentrantLockDemo
private int value;
private Lock lock = new ReentrantLock();
public int getNext ()
lock.lock();
try {
return value++;
}finally {
lock.unlock();
}
}
3.4 ReadWriteLock 锁 在某些情况下,读和写操作并不一定一样多,所以就诞生了这个读写锁。
ReentrantReadWriteLock 时ReadWriteLock的一个实现,通过这个实例,可以获取到对应的读锁和写锁,从而根据实际需求使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadAndWriteDemo
private Map<String, String> map = new HashMap<>();
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
private Lock readLock = lock.readLock();
private Lock writeLock = lock.writeLock();
public String get (String key)
readLock.lock();
System.out.println(Thread.currentThread().getName() + " 读取锁开始 。。。。。。 " );
try {
Thread.sleep(300 );
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
return map.get(key);
} finally {
readLock.unlock();
System.out.println(Thread.currentThread().getName() + " 读取锁结束 。。。。。。" );
}
}
public void put (String key, String value)
writeLock.lock();
System.out.println(Thread.currentThread().getName() + " 写入锁开始 。。。。。。 " );
try {
Thread.sleep(300 );
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
map.put(key,value);
}finally {
writeLock.unlock();
System.out.println(Thread.currentThread().getName() + " 写入锁结束 。。。。。。 " );
}
}
private boolean isUpdate = true ;
public String readWrite (String key,String value)
readLock.lock();
if (isUpdate){
readLock.unlock();
writeLock.lock();
map.put(key,value);
readLock.lock();
writeLock.unlock();
}
try {
return map.get(key);
}finally {
readLock.unlock();
}
}
public static void main (String[] args)
ReadAndWriteDemo demo = new ReadAndWriteDemo();
readWriteDemo(demo);
}
public static void readWriteDemo (ReadAndWriteDemo demo)
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve1" ,"liu" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.get("steve1" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve2" ,"liu" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.get("steve1" );
}
}).start();
}
public static void readDemo (ReadAndWriteDemo demo)
demo.put("steve1" ,"liu" );
new Thread(new Runnable() {
@Override
public void run ()
demo.get("steve1" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.get("steve1" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.get("steve1" );
}
}).start();
}
public static void writeDemo (ReadAndWriteDemo demo)
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve" ,"liu" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve" ,"liu" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve" ,"liu" );
}
}).start();
new Thread(new Runnable() {
@Override
public void run ()
demo.put("steve" ,"liu" );
}
}).start();
}
}
3.5 StampedLock 锁 ReentrantReadWriteLock 在沒有任何读写锁时,才可以取得写入锁,这可用于实现了悲观读取(Pessimistic Reading),即如果执行中进行读取时,经常可能有另一执行要写入的需求,为了保持同步,ReentrantReadWriteLock 的读取锁定就可派上用场。
然而,如果读取执行情况很多,写入很少的情况下,使用 ReentrantReadWriteLock 可能会使写入线程遭遇饥饿(Starvation)问题,也就是写入线程吃吃无法竞争到锁定而一直处于等待状态。
StampedLock控制锁有三种模式(写,读,乐观读),一个StampedLock状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据stamp,它用相应的锁状态表示并控制访问,数字0表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。
所谓的乐观读模式,也就是若读的操作很多,写的操作很少的情况下,你可以乐观地认为,写入与读取同时发生几率很少,因此不悲观地使用完全的读取锁定,程序可以查看读取资料之后,是否遭到写入执行的变更,再采取后续的措施(重新读取变更信息,或者抛出异常) ,这一个小小改进,可大幅度提高程序的吞吐量!!
3.6 重入锁 当被锁住的方法里面调用了其他也加了锁的方法时,如果可以调用成功,就说这个锁是可重入锁,这个调用操作成为锁重入。话不多说,看代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class ThreadReentrant
public synchronized void a ()
System.out.println("a ..." );
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
b();
}
public synchronized void b ()
System.out.println("b ... " );
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main (String[] args)
ThreadReentrant threadReentrant1 = new ThreadReentrant();
new Thread(() -> threadReentrant1.b()).start();
new Thread(() -> threadReentrant1.a()).start();
}
}
3.7 自旋锁 就是等待其他线程结束的一个操作,相当于while-true。话不多说,看代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public static void main (String[] args)
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "线程开始 。。。 " );
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "线程结束 。。。 " );
}).start();
while (Thread.activeCount() != 2 ){
}
System.out.println("over 。。。" );
}
3.8 死锁 就是两个线程,两个资源之间的一种竞争关系,A线程持有资源A,接下来想要取到资源B,但是B线程同时持有资源B,想要获取资源A。然后两个线程一直处于等待状态,导致死锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public class DeadLockDemo
private static final String A = "A" ;
private static final String B = "B" ;
public static void main (String... args)
new DeadLockDemo().deadLock();
}
private void deadLock ()
Thread thread1 = new Thread(new Runnable() {
@Override
public void run ()
synchronized (A) {
try {
Thread.sleep(2 );
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B){
System.out.print("1" );
}
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run ()
synchronized (B){
synchronized (A){
System.out.println("2" );
}
}
}
});
thread1.start();
thread2.start();
}
}
3.9 AQS的原理 AQS是jdk8并发包里的抽象类AbstractQueuedSynchronizer的简称。先来看看他的文档 ,看看他的设计:
为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件,等等)提供一个框架。此类的设计目标是成为依靠单个原子 int 值来表示状态的大多数同步器的一个有用基础。子类必须定义更改此状态的受保护方法,并定义哪种状态对于此对象意味着被获取或被释放。假定这些条件之后,此类中的其他方法就可以实现所有排队和阻塞机制。子类可以维护其他状态字段,但只是为了获得同步而只追踪使用 getState()、setState(int) 和 compareAndSetState(int, int) 方法来操作以原子方式更新的 int 值。
这一段表明了它的作用是用于实现相关同步器,还讲了部分原理,他的内部实现是依靠一个FIFO的等待队列,来实现对象的等待唤醒机制。内部有一个int类型的变量保存对象的同步状态。
应该将子类定义为非公共内部帮助器类,可用它们来实现其封闭类的同步属性。类 AbstractQueuedSynchronizer 没有实现任何同步接口。而是定义了诸如 acquireInterruptibly(int) 之类的一些方法,在适当的时候可以通过具体的锁和相关同步器来调用它们,以实现其公共方法。
这一段表明了它的使用方法。
此类支持默认的独占 模式和共享 模式之一,或者二者都支持。处于独占模式下时,其他线程试图获取该锁将无法取得成功。在共享模式下,多个线程获取某个锁可能(但不是一定)会获得成功。此类并不“了解”这些不同,除了机械地意识到当在共享模式下成功获取某一锁时,下一个等待线程(如果存在)也必须确定自己是否可以成功获取该锁。处于不同模式下的等待线程可以共享相同的 FIFO 队列。通常,实现子类只支持其中一种模式,但两种模式都可以在(例如)ReadWriteLock 中发挥作用。只支持独占模式或者只支持共享模式的子类不必定义支持未使用模式的方法。
这一段表明AQS支持两种锁模式,一个是独占模式,典型的应用是ReentrantLock,另一种是共享模式,这个例子就比较多了,如CountDownLatch和CyclicBarrier。然后介绍了一些常见的使用情景。
为了将此类用作同步器的基础,需要适当地重新定义以下方法,这是通过使用 getState()、setState(int) 和/或 compareAndSetState(int, int) 方法来检查和/或修改同步状态来实现的:
tryAcquire(int)
tryRelease(int)
tryAcquireShared(int)
tryReleaseShared(int)
isHeldExclusively()
默认情况下,每个方法都抛出 UnsupportedOperationException。这些方法的实现在内部必须是线程安全的,通常应该很短并且不被阻塞。定义这些方法是使用此类的 唯一 受支持的方式。其他所有方法都被声明为 final,因为它们无法是各不相同的。
这一段就是告诉你要实现自定义的同步器需要适当的重写这几个方法.下面我们就 ReentrantLock 这个独占锁类来看看AQS给我们提供的功能吧。1
2
3
public void lock ()
sync.lock();
}
看源码可以知道sync是ReentrantLock内部的一个AQS实现的抽象类,它还有两个实现类NonfairSync和FairSync,就是公平锁和非公平锁的实现。它的lock方法是个抽象方法,所以我们需要找到它的默认实现,看源码可知默认实现是非公平锁,所以我们就看非公平锁的lock方法实现
1
2
3
4
5
6
final void lock ()
if (compareAndSetState(0 , 1 ))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1 );
}
这里首先用CAS方法尝试将State的值变为1(state就是维持同步器的状态的那个int值,CAS内部实现可以理解为一个while无限循环,当当前的值等于expect时,会将当前的值设置为update的值),设置成功后就调用setExclusiveOwnerThread方法,并将当前线程传入进去,这个方法就是将传入的线程赋值给了exclusiveOwnerThread 变量,这个变量就是保存的当前的线程。设置失败后就会调用AQS的acquire方法,来看这个方法的实现
1
2
3
4
5
public final void acquire (int arg)
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
arg就是1,这个是state的值。表示同步器的状态计数器。如果if里面的条件不成立,这个对象(ReentranLock实例)就不会上锁(state没增加就表明当前lock失败)。我们继续来看它的tryAcquire(arg)的实现,这个方法内部只有一行,调用了nonfairTryAcquire方法。来看源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
final boolean nonfairTryAcquire (int acquires)
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0 ) {
if (compareAndSetState(0 , acquires)) {
setExclusiveOwnerThread(current);
return true ;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0 )
throw new Error("Maximum lock count exceeded" );
setState(nextc);
return true ;
}
return false ;
}
首先令current为当前的变量,将当前的state赋值给c,当state的值等于0时,会进行一次CAS,将state修改为acquires的值,也就是1。返回true。当state的值不为0的时候并且当前线程等于内存中存的值(getExclusiveOwnerThread 方法返回的就是exclusiveOwnerThread的值)时(这一步判断是为了防止这不是重入进来的),将c 和 acquires 的值相加并赋值给nextc变量,当nextc的值出现小于0的情况时,表明内存发生了溢出。抛出异常。如果没发生内存溢出就将state的值设为(c + acquires),返回true; 还有其它的情况返回false。 当tryAcquire(arg)方法返回true时,那么表明acquire方法获取成功了。当tryAcquire返回false,我们再来看acquireQueued(addWaiter(Node.EXCLUSIVE), arg))这个方法,首先来看addWaiter的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
private Node addWaiter (Node mode)
Node node = new Node(Thread.currentThread(), mode);
Node pred = tail;
if (pred != null ) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
这里面的node表示的是FIFO里面的一个个对象,这个FIFO是通过双向链表实现的。传入的mode是Node.EXCLUSIVE,看源码可知它是null的,表示的是独占模式下的一个等待节点(Node源码自行查看,这里就不提了)。然后令pred = tail节点,如果tail节点不为空,则会尝试将node节点设置为尾节点(tail),设置失败就只是一个单向链表指向,设置成功就变成双向链表了并返回node。如果tail节点为空(表明刚初始化)。执行enq(node)方法,继续来看它的源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private Node enq (final Node node)
for (;;) {
Node t = tail;
if (t == null ) {
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
有了前面的基础,再看这段代码会觉得很简单,就是一个无限循环,强制保证node这个传入的节点设置为tail节点。回到上一个方法addWaiter, 往下执行就是返回这个node了。在回溯到acquire方法,这时候是到了acquireQueued(addWaiter(Node.EXCLUSIVE), arg))这个方法了,来看它的源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
final boolean acquireQueued (final Node node, int arg)
boolean failed = true ;
try {
boolean interrupted = false ;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null ;
failed = false ;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true ;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
这里的两个参数我们可知node为链表的尾节点(FIFO的尾部),arg为1.看这个无限for循环,首先令p为node的前一个节点(predecessor方法就是返回前一个节点),判断p是否为head节点并且试图设置容器的状态值,两个条件都成立就执行setHead方法将node节点设置为head节点,并将p节点的下一个节点设置为null,就是解除了node节点和node前一个节点的关联关系。来看看setHead方法1
2
3
4
5
private void setHead (Node node)
head = node;
node.thread = null ;
node.prev = null ;
}
这里将node节点的部分属性都设置为null了。返回上一个调用方法acquireQueued,这里将failed变量设置为false,并返回了一个false结果(根据变量名可以猜到这是一个表示当前锁没被中断的结果),结束了无限循环。如果前面的条件不成立,进入到shouldParkAfterFailedAcquire(p, node)和parkAndCheckInterrupt() 两个方法的判断,这里主要是判断锁状态是否被中断。看看他们的源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
private static boolean shouldParkAfterFailedAcquire (Node pred, Node node)
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
return true ;
if (ws > 0 ) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0 );
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false ;
}
这一段首先令ws变量为节点pred的waitStatus(等待状态值),它共有以下几种情形
CANCELLED(1) 表示线程退出了
SIGNAL(-1) 表示线程状态为等待唤醒(unparking)
CONDITION(-2) 表示线程在等待指定的条件(condition)成立
PROPAGATE(-3) 表示一个共享的释放锁应该传播给其它的节点
0 默认值,无意义1
2
3
4
private final boolean parkAndCheckInterrupt ()
LockSupport.park(this );
return Thread.interrupted();
}
这段代码简单点理解就是返回当前线程是否被中断。我们可以继续看看park方法的实现1
2
3
4
5
6
public static void park (Object blocker)
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false , 0L );
setBlocker(t, null );
}
这里就是将blocker对象设置为阻塞状态,这段代码有点难以理解,以后再看看。
参考资料:JAVA CAS原理深度分析 JAVA并发编程学习笔记之Unsafe类
4.线程间通信 这里就举个生产者与消费者的例子来演示线程间的通信。
4.1 wait/notify 方法 wait是一个等待方法,和本文开头的流程图说的一样,当线程执行到wait时,进入到等待状态,并同时释放对象的锁,然后只能等待对象的notify或者notifyAll方法唤醒。如果这时候有关闭线程的操作发出,则会抛出 InterruptedException 异常。被唤醒后会继续执行后面的代码。
4.2 await/signal 方法 这两个比上面的两个方法细粒度更小一点,可以指定对象等待和唤醒。可控度更高一点,具体看示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
public class ConditionDemo
private int signal = 0 ;
Lock lock = new ReentrantLock();
Condition a = lock.newCondition();
Condition b = lock.newCondition();
Condition c = lock.newCondition();
private void a ()
try {
lock.lock();
while (signal != 0 ){
try {
a.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("a方法执行" );
signal ++ ;
b.signal();
}finally {
lock.unlock();
}
}
private void b ()
try {
lock.lock();
while (signal != 1 ){
try {
b.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("b方法执行" );
signal ++ ;
c.signal();
}finally {
lock.unlock();
}
}
private void c ()
try {
lock.lock();
while (signal != 2 ){
try {
c.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("c方法执行" );
signal = 0 ;
a.signal();
}finally {
lock.unlock();
}
}
public static void main (String[] args)
ConditionDemo demo = new ConditionDemo();
ExecutorService service = Executors.newFixedThreadPool(3 );
service.execute(new Runnable() {
@Override
public void run ()
while (true ) {
demo.c();
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
service.execute(new Runnable() {
@Override
public void run ()
while (true ) {
demo.b();
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
service.execute(new Runnable() {
@Override
public void run ()
while (true ) {
demo.a();
try {
Thread.sleep(1000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
service.shutdown();
}
}
5.并发工具类(jdk8) 5.1 CountDownLatch countDownLatch 简单来说就是一个线程等待其它N个线程执行到某个状态的一个计数器,也就是一等多。其它线程完成指定的任务后(countDown方法)还可以继续做它自己的事,而等待的线程需要等所有的线程完成指定的任务时才能继续它接下来的事。看示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class CountDownLatchDemo
public static void main (String[] args) throws InterruptedException
CountDownLatch countDownLatch = new CountDownLatch(3 );
CountDownLatchDemo demo = new CountDownLatchDemo();
long start = System.currentTimeMillis();
for (int i=0 ; i< 3 ; i++){
new Thread(new Runnable() {
@Override
public void run ()
demo.execute(countDownLatch);
}
}).start();
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("所有线程准备完毕,准备时间: " + (end-start) + " 开始执行下一段任务。" );
}
public void execute (CountDownLatch countDownLatch)
System.out.println(Thread.currentThread().getName() + "执行2秒任务" );
try {
Thread.sleep(2000 );
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName() + " 线程 执行完毕,返回主线程执行" );
}
}
5.2 CyclicBarrier CyclicBarrier 相当于一个栏杆,当线程都到达了栏杆位置处(await方法)才可以继续往下执行,当一个没到达(执行出异常)就不放行。简单来说就是多等多。N个线程互相等待。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class CyclicBarrierDemo
private void eatting (CyclicBarrier cyclicBarrier, Random random)
System.out.println(Thread.currentThread().getName() + "ready to eat" );
try {
Thread.sleep(random.nextInt(2000 ));
cyclicBarrier.await();
}catch (Exception e){
}
System.out.println(Thread.currentThread().getName() + " finally, I just can eat now." );
}
public static void main (String[] args)
CyclicBarrierDemo demo = new CyclicBarrierDemo();
Random random = new Random();
CyclicBarrier cyclicBarrier = new CyclicBarrier(4 , new Runnable() {
@Override
public void run ()
System.out.println("all member are rady to eat, Then just go to eat" );
}
});
ExecutorService executor = Executors.newCachedThreadPool();
for (int i=0 ;i < 4 ; i++){
executor.execute(new Runnable() {
@Override
public void run ()
demo.eatting(cyclicBarrier,random);
}
});
}
executor.shutdown();
}
}
5.3 Semaphore Semaphore 相当于一个停车库,当车太多的时候(并发访问),每次只能放行指定数量的车(构造函数指定)。当一辆车走后(release方法),才会放另一辆车进来(acquire方法)。相当于是一个限制资源访问量的工具类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class SemaphoreDemo
private void demo (Semaphore semaphore)
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " 开始执行1s的任务" );
Thread.sleep(1000 );
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main (String[] args)
Semaphore semaphore = new Semaphore(10 );
SemaphoreDemo demo = new SemaphoreDemo();
ExecutorService exec = Executors.newCachedThreadPool();
long start = System.currentTimeMillis();
for (int i=0 ;i<100 ;i++){
exec.execute(new Runnable() {
@Override
public void run ()
demo.demo(semaphore);
}
});
}
exec.shutdown();
while (Thread.activeCount() != 2 ){}
long end = System.currentTimeMillis();
System.out.printf("任务执行完毕,共耗时: " + (end-start));
}
}
5.4 Exchanger Exchanger的使用场景有两个线程执行的结果进行比较(exchange方法),还有就是线程间交换对象。相当于一个栅栏,当两个线程到这里之后就进行数据之间的交换。看示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
public class ExchangerDemo
private void a (Exchanger<Integer> exch)
System.out.println(Thread.currentThread().getName() + " 的a方法正在执行抓取任务。。。" );
try {
Thread.sleep(2500 );
Integer result = 12345 ;
System.out.println(Thread.currentThread().getName() + " 的a方法抓取任务结束,结果为: " + result);
Integer res = exch.exchange(result);
System.out.println("a方法两个线程的结果是否相等: " + res.equals(result));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void b (Exchanger<Integer> exch)
System.out.println(Thread.currentThread().getName() + " 的b方法正在执行抓取任务。。。" );
try {
Thread.sleep(2500 );
Integer result = 12344 ;
System.out.println(Thread.currentThread().getName() + " 的b方法抓取任务结束,结果为: " + result);
Integer res = exch.exchange(result);
System.out.println("b方法两个线程的结果是否相等: " + res.equals(result));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void c (Exchanger<List<String>> exchanger)
List<String> list = new CopyOnWriteArrayList<String>(){
{
add("steve" );
add("steve1" );
add("steve2" );
add("steve3" );
}
};
System.out.println("c方法负责生产对象" );
try {
Thread.sleep(1000 );
System.out.println("a 方法生产完毕" );
exchanger.exchange(list);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void d (Exchanger<List<String>> exchanger)
List<String> list = null ;
System.out.println("d方法负责消费对象" );
try {
Thread.sleep(2000 );
list = exchanger.exchange(list);
System.out.println("d方法对象交换完毕。。。" );
list.stream().forEach(e -> System.out.print("d " + e + " " ));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main (String[] args)
ExecutorService exec = Executors.newFixedThreadPool(2 );
ExchangerDemo demo = new ExchangerDemo();
Exchanger<Integer> exch = new Exchanger<>();
Exchanger<List<String>> exchanger = new Exchanger<>();
exec.execute(new Runnable() {
@Override
public void run ()
demo.c(exchanger);
}
});
exec.execute(new Runnable() {
@Override
public void run ()
demo.d(exchanger);
}
});
exec.shutdown();
}
}
参考资料:Java并发新构件之Exchanger Java并发编程:CountDownLatch、CyclicBarrier和Semaphore
5.5 CountDownLatch,CyclicBarrier,Semaphore 源码分析 前面说过,在jdk8里面几乎所有的并发容器都是基于AQS(AbstractQueuedSynchronizer)实现的。这里首先来看CountDownLatch中对AQS的应用(共享锁实现)。1
2
3
public void countDown ()
sync.releaseShared(1 );
}
来看sync类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
private static final class Sync extends AbstractQueuedSynchronizer
private static final long serialVersionUID = 4982264981922014374L ;
Sync(int count) {
setState(count);
}
int getCount ()
return getState();
}
protected int tryAcquireShared (int acquires)
return (getState() == 0 ) ? 1 : -1 ;
}
protected boolean tryReleaseShared (int releases)
for (;;) {
int c = getState();
if (c == 0 )
return false ;
int nextc = c-1 ;
if (compareAndSetState(c, nextc))
return nextc == 0 ;
}
}
}
可以知道sync是AQS抽象类的一个实现,countDown方法调用了AQS的一个releaseShared方法,并传入了一个1,接下来看这个方法1
2
3
4
5
6
7
public final boolean releaseShared (int arg)
if (tryReleaseShared(arg)) {
doReleaseShared();
return true ;
}
return false ;
}
这里调用了tryReleaseShared 方法判断,如果结果为false,方法返回false。这个判断方法在sync里面被重写了,下面来分析这段代码1
2
3
4
5
6
7
8
9
10
11
protected boolean tryReleaseShared (int releases)
for (;;) {
int c = getState();
if (c == 0 )
return false ;
int nextc = c-1 ;
if (compareAndSetState(c, nextc))
return nextc == 0 ;
}
}
首先getState方法获取同步器的状态值(在这里是初始化CountDownLatch时传入的值),当状态值为0的时候,返回false,退出循环,当状态值不为0的时候,令nextc = c - 1,调用compareAndSetState(CAS)方法尝试将内存中的state值设置为nextc,如果成功赋值,判断nextc是否为0.并返回结果。这里的compareAndState就是我们常说的CAS。这里不管结果,只需关注state的值是否减少了。当c == 1 的时候,进入到doReleaseShared方法,看源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
private void doReleaseShared ()
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0 ))
continue ;
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0 , Node.PROPAGATE))
continue ;
}
if (h == head)
break ;
}
}
看过上面分析的AQS源码看这段代码就很简单了,这里主要做的事是当条件成立时将FIFO队列里面的头节点的下一个节点设置为等待状态。看unparkSuccessor的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
private void unparkSuccessor (Node node)
int ws = node.waitStatus;
if (ws < 0 )
compareAndSetWaitStatus(node, ws, 0 );
Node s = node.next;
if (s == null || s.waitStatus > 0 ) {
s = null ;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0 )
s = t;
}
if (s != null )
LockSupport.unpark(s.thread);
}
接下来继续看它的await方法1
2
3
public void await () throws InterruptedException
sync.acquireSharedInterruptibly(1 );
}
看AQS的实现1
2
3
4
5
6
7
public final void acquireSharedInterruptibly (int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0 )
doAcquireSharedInterruptibly(arg);
}
当没发生中断的时候,看sync实现的tryAcquireShared方法
1
2
3
protected int tryAcquireShared (int acquires)
return (getState() == 0 ) ? 1 : -1 ;
}
这里很简单,就是判断当前同步器的状态值是否为0,若为0.表示其他线程都到达了指定的位置,然后调用AQS的doAcquireSharedInterruptibly方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
private void doAcquireSharedInterruptibly (int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true ;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0 ) {
setHeadAndPropagate(node, r);
p.next = null ;
failed = false ;
return ;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
具体分析和上面AQS差不多,主要作用是把FIFO队列的node前一节点设置为等待唤醒状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
private int dowait (boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this .lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
int index = --count;
if (index == 0 ) {
boolean ranAction = false ;
try {
final Runnable command = barrierCommand;
if (command != null )
command.run();
ranAction = true ;
nextGeneration();
return 0 ;
} finally {
if (!ranAction)
breakBarrier();
}
}
for (;;) {
try {
if (!timed)
trip.await();
else if (nanos > 0L )
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
if (timed && nanos <= 0L ) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
这个它的await里面调用的doAwait方法。首先对这段执行的代码进行lock操作,然后根据Generation的boolean属性broken判断是否被中断(初始化为false)。下一步判断线程是否被中断,如果被中断,将broken值设置true,并唤醒所有在等待中的线程,令等待中线程的数量等于初始化CyclicBarrier传入的值。如果没被中断,往下执行,令index等于count-1,index表示的是等待中线程的数量。如果index等于0,表示没有线程处在等待状态了,那么就执行这个线程命令。接下来看这个无限循环代码。timed默认为false(await方法传入),这个awaitNanos方法表示当前线程等待指定的nanos时间被唤醒。后面还有一系列操作,也挺简单的。就不细说了。
Read More